




 |
Phần 2: Cấu hình cổng truy cập tài nguyên điện tử từ xa trong MetaLib
>> Cổng thư viện hướng tới Web Ngữ nghĩa – Phần 1 Như đã giải thích ở phần trước, MetaLib không giống như những sản phẩm cổng thư viện khác, nó sử dụng một kho dữ liệu cơ sở. Cơ sở dữ liệu KnowledgeBase của MetaLib lưu trữ thông tin tài nguyên sẵn có đối với một thư viện. Mỗi tài nguyên được tìm kiếm thông qua MetaLib sẽ được trình bày như một mục trong KnowledgeBase.
|
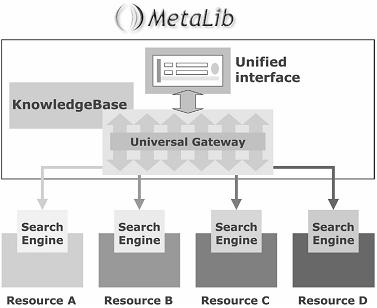
Lưu trữ thông tin ở nhiều cấp độ tương thích với một KnowledgeBase trung tâm và có tính toàn cầu, nó phục vụ cho những cài đặt và cấu hình tài nguyên theo đặc thù của mỗi thư viện. Cách thức này cho phép thư viện cập nhật từ cở sở dữ liệu tài nguyên trung tâm này trong khi vẫn duy trì cơ sở dữ liệu và thông tin cấu hình nội bộ tại mỗi site. Các công cụ dựa trên Web sẽ đi cùng kho dữ liệu để cho phép tạo ra và duy trì những thực thể tài nguyên mục tiêu, nhập và xuất thông tin, sự tương thích thông tin trong một site hoặc một đơn vị quản trị trong một site, đồng thời cung cấp thông tin như vậy cho cả người quản trị và chương trình khi cần thiết (Xem Hình 1).
Hình 1: Cổng Universal Gateway tương tác với tài nguyên mục tiêu khác nhau để cung cấp cho người dùng kết quả, sự tương tác này dựa trên dữ liệu và quy luật của KnowlegeBase
 |
Có hai dạng thông tin được lưu trữ trong KnowledgeBase , đó là thông tin mô tả và thông tin chức năng. Trong khi thông tin chức năng cho phép tương tác giữa Universal Gateway và tài nguyên cho mục đích tìm kiếm và truy xuất thông tin, thì thông tin mô tả lại cho phép cổng tài nguyên này trợ giúp người dùng xác định vị trí tài nguyên phù hợp thông qua một lớp siêu dữ liệu bổ sung thêm.
Thông tin mô tả
Từ góc độ của thông tin mô tả, KnowledgeBase là một bộ sưu tập siêu dữ liệu về tài nguyên. Mỗi tài nguyên được biên mục trong KnowledgeBase, là kết quả của sự hợp tác giữa Ex Libris, một đại diện của ở phía người sử dụng tài nguyên, và đôi khi cũng là các thành viên của tổ chức thư viện, mỗi một thành viên như vậy có quyền giám sát và thêm vào những mục tiêu mới. Mối quan tâm của thủ thư về sự tổ chức thông tin như vậy có thể thấy trong những sáng kiến gần đây, như UK Collection Descriptive Focus, một tổ chức được trợ giúp tài chính bởi Thư viện Quốc gia Anh (The British Library), JISC (Joint Information Systems Committee), Research Libraries Programme, and Resource (UKOLN, 2002).
Thông tin mô tả này cho phép một nhà nghiên cứu xác định được những tài nguyên phù hợp với chủ đề cụ thể nào đó. Các thủ thư sử dụng thông tin mô tả như là một công cụ để trình bày bộ sưu tập của thư viện theo một cách thức toàn diện nhất. Ngoài việc cung cấp cho người dùng dữ liệu giàu thông tin, trung thực, như sự bao phủ một tài nguyên cụ thể và ngôn ngữ của nó, các thủ thư còn có thể phân loại tài nguyên và gán những từ khóa tới chúng để trình bày chúng theo một bối cảnh đúng với một người dùng cụ thể. Thủ thư có thể cấu hình chuyển giao tài nguyên đến người dùng trên cơ sở phân nhóm người dùng.
MetaLib sử dụng siêu dữ liệu của tài nguyên để cho phép người dùng xác định vị trí tài nguyên mà họ quan tâm. Ví dụ, một danh mục tài nguyên mặc định được biên tập bởi thủ thư hình thành lên một cơ sở danh mục tài nguyên cá nhân của một sinh viên luật nào đó. Sinh viên luật này sau đó có thể sửa đổi danh mục này và thêm vào những tài nguyên khác mà họ quan tâm. Khi tìm kiếm thông tin, sinh viên này có thể lựa chọn tài nguyên từ một danh mục cá nhân hóa của mình hoặc sử dụng chức năng “Resource Locator” trong MetaLib để xác định vị trí tài nguyên cho một câu hỏi truy vấn cụ thể. Sinh viên này cũng có thể chọn làm việc với một trong những bộ sưu tập tài nguyên được thủ thư định nghĩa trước cho toàn hệ thống hay cả thư viện.
Thông tin mô tả trong KnowledgeBase của MetaLib được con người cài đặt, và dành cho con người. Trình bày một số lượng tài nguyên lớn tới người dùng không phải là một nhiệm vụ dễ dàng, và các tổ chức thư viện đang phấn đấu để cung cấp những giao diện thân thiện nhằm trình bày bộ sưu tập của mình theo cách người dùng có thể tìm thấy ngay những gì họ cần. Giải pháp dựa trên các trang HTML tĩnh khó có thể trình bày và duy trì bời vì sự thay đổi thường xuyên trong các bộ sưu tập tài nguyên và trong chính mỗi tài nguyên đó. Hơn thế nữa, mỗi tài nguyên có thể liên quan đến nhiều lĩnh vực học thuật hoặc bối cảnh cụ thể, bởi vậy sự cập nhật cần thiết phải được triển khai phù hợp.
Được lưu trữ trong KnowledgeBase cho mỗi tài nguyên mục tiêu, thông tin mô tả cho phép hiển thị năng động tài nguyên theo bất kỳ ngữ cảnh nào, mà không cần bất kỳ sự sửa đổi tới chương trình, hoặc code của trang HTML. Khi một tài nguyên được đưa thêm vào hệ thống, tài nguyên này được trình bày phù hợp đối với người dùng bất cứ khi nào từ thời điểm đó trở đi.
Phần thông tin mô tả trong KnowledgeBase bao gồm những thông tin chung như tên đầy đủ của nguồn tài nguyên, các tên gọi khác, chính sách truy cập của nhà xuất bản hay nhà cung cấp nội dung (liệu tài nguyên đó được truy cập miễn phí hay phải trả phí), dạng tài nguyên (ví dụ như mục lục thư viện, cơ sở dữ liệu chỉ mục tóm tắt, hoặc đầu tìm kiếm Web), người tạo ra tài nguyên và xuất bản tài nguyên. Hiển nhiên, một sự mô tả tài nguyên, phạm vi của tài nguyên, độ sâu hồi cố, và ngôn ngữ – tất cả đều được định nghĩa trong cơ sở dữ liệu trung tâm – cũng được đưa vào.
Các thông tin bổ sung thêm có thể được quyết định theo nhu cầu cụ thể của từng thư viện. Thông tin như vậy bao gồm thông tin về các tài nguyên sẽ được phân loại thế nào để trình bày tới người dùng, phù hợp với quyền của người dùng, và những thuộc tính trao quyền truy cập đối với các tài nguyên.
Thông tin mô tả trong KnowlegeBase là một chức năng của môi trường tài nguyên cho một tổ chức thư viện và nó được làm sẵn có thông qua việc duy trì kho dữ liệu này, điều này cũng nằm trong sự quyết định của thư viện. Một khi các cổng thư viện đạt tới một điểm mà ở đó các tài nguyên mục tiêu trình bày những cấu trúc và quy luật suy diễn về dữ liệu riêng, và những khả năng phần mềm riêng của mỗi tài nguyên, thì chúng ta cần phải đánh giá lại chức năng của lớp thông tin nhạy cảm này của thư viện.
Hầu hết thông tin mô tả đều sẵn có đối với người dùng một cách rõ ràng hoặc là ẩn chứa bên trong. Bất cứ lúc nào, một người dùng cũng có thể truy vấn thông tin về một tài nguyên. Khi tìm kiếm một tài nguyên cụ thể, người dùng mong muốn thấy tài nguyên hiển thị theo sự phân loại và tận dụng được thông tin đã lưu trữ trước đó. Người dùng chỉ thấy được tài nguyên mà một thư viện cài đặt trước theo những quy luật trao quyền người dùng để cho phép họ có thể xem được.
Thông tin chức năng
Thông tin chức năng trong KnowlegeBase cho mỗi tài nguyên bao gồm:
· Thông tin về cài đặt các quy luật để biên dịch và truyền tải một câu hỏi truy vấn. Thông tin này được cung cấp trên 3 cấp độ: Phương pháp truyển tải (vd., tương tác máy chủ tới máy chủ, hoặc HTTP); khổ mẫu mà câu hỏi truy vấn đó được truyền tải (vd., nó có thể được gửi như câu hỏi truy vấn Z39.50 hoặc như một yêu cầu HTTP, hoặc được mã hóa trên đường dẫn URL hoặc gửi trong một tài liệu XML); xây dựng lại chính câu hỏi truy vấn đó. Việc xây dựng lại câu hỏi truy vấn liên quan đến khả năng thích nghi một cú pháp truy vấn, khả năng ánh xạ các chỉ mục tìm kiếm, và khả năng chuyển đổi ký tự.
· Thông tin cài đặt các quy luật cho biên dịch kết quả có được từ một tài nguyên. Thông tin này giống như thông tin của câu hỏi truy vấn và bao gồm quy luật cho phép biên dịch các biểu ghi có sự khác nhau về cấu trúc vật lý và cấu trúc logic, khổ mẫu biên mục (như MARC và MAB), và các bộ ký tự. Một khi các biểu ghi được biên dịch và chuyển đổi sang một khổ mẫu nội bộ thống nhất, thì các công cụ được lập trình tự động có thể hiện thị kết quả tới người dùng theo cùng một cách, so sánh các biểu ghi từ những tài nguyên khác biệt nhau, cung cấp dịch vụ phù hợp cho từng loại biểu ghi cụ thể và nhiều dịch vụ khác nữa. Với khả năng biên dịch kết quả này, một nguồn chất liệu chính sẽ giúp tạo ra một đường dẫn OpenURL nhằm chuyển giao các tài nguyên mục tiêu khác.
Tiêu chuẩn OpenURL của NISO (NISO Committee, AX, n.d) cho phép máy chủ nối kết SFX cung cấp các nối kết phù hợp ngữ cảnh tới các dịch vụ phù hợp và tài nguyên liên quan. Một khi siêu dữ liệu có được từ những tài nguyên được biên dịch, thì một đường dẫn OpenURL được sinh ra và được chuyển tới máy chủ nối kết của thư viện theo yêu cầu của người dùng. Sau đó, máy chủ nối kết sẽ đánh giá siêu dữ liệu này, và theo quyền sử dụng của người dùng, đưa ra một trình nối kết do thư viện cấu hình sẵn (Van de Sompel và Beit-Arie, 2001).
Ngoài những phần tử vừa mới mô tả, thông tin chức năng của KnowledgeBase chứa đựng một bộ quy luật được chương trình xử lý liên tục theo chuỗi nhằm hoàn thành ngay một nhiệm vụ vừa được đưa ra bởi người dùng; ví như, chuyển đi một câu hỏi truy vấn và xử lý kết quả trả về. Nhiều bảng chuyển đổi giúp chương trình biên dịch các quy luật của mỗi loại tài nguyên cụ thể và hành động theo những quy luật này cho cả xử lý cấu hỏi truy vấn và dữ liệu truy xuất về.
Quy luật áp dụng cho các câu hỏi truy vấn
Berners-Lee et al. (2001) phát biểu rằng ”để cho phép Web ngữ nghĩa đạt được chức năng của nó, các máy tính nhất thiết phải truy cập các bộ sưu tập thông tin có cấu trúc và những bộ quy luật suy luận mà chúng có thể sử dụng để thực hiện sự suy diễn tự động ’’. Một ví dụ khả thi về sự thực hiện những quy luật suy luận như vậy là sự sử dụng một bộ chuyển đổi để chuyển câu hỏi truy vấn của người dùng vào một khổ mẫu phù hợp với đặc tính kỹ thuật của một đầu tìm kiếm tài nguyên.
Chúng ta hãy xem xét một minh họa đơn giản. Một tài nguyên mục tiêu cụ thể nào đó yêu cầu tên tác giả trong câu hỏi truy vấn phải theo mẫu sau :
< LAST NAME > – < FIRST NAME > ?
Nếu một người dùng nhập vào một tên như là “smith, John” (trong cú pháp tìm kiếm MetaLib) tên này phải được chuyển đổi sang “SMITH-J?”. Trong KnowlegdeBase, những chuyển đổi sau đây là những quy luật mà Universal Gateway xử lý liên tục theo chuỗi, được gán cho mỗi tài nguyên cụ thể:
(1) Thay đổi chuỗi ký tự từ chữ thường sang chữ hoa
(2) Loại bỏ dấu phẩy
(3) Thay thế những ký tự cuối cùng và để lại ký tự đầu tiên
(4) Thay thế khoảng trống giữa hai chữ bằng một dấu gạch ngang
(5) Đánh một dấu hỏi vào cuối từ
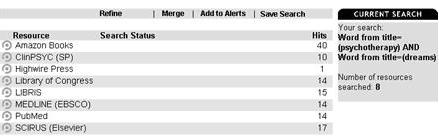
· Bằng việc thực hiện một quy luật sẵn có như vậy, MetaLib thể hiện logic một quy trình chuyển đổi và làm cho quy trình này dễ dàng hơn đối với thủ thư để có thể theo dõi và điều chỉnh khi cần thiết – không giống như thói quen lập trình mà người ta thường tạo ra một hộp đen (Black box) trong hệ thống. Đối với MetaLib, một thủ thư không có kiến thức lập trình có thể dễ dàng cài đặt quy luật áp dụng cho mỗi tài nguyên cụ thể; chương trình sau đó sẽ kích hoạt quy luật để tạo một câu hỏi truy vấn và theo dõi từng bước theo đúng với tài nguyên mục tiêu ở xa. Giai đoạn tiếp theo MetaLib giúp thủ thư xác định chỉ những kết quả mong muốn và nhân tố quyết định những quy luật nào sẽ được áp dụng (Xem Hình 2).
Hình 2: Một câu hỏi truy vấn được chuyển tới những tài nguyên khác biệt và được thích nghi đến mức cần thiết cho mỗi tài nguyên
 |
Những quy luật áp dụng cho quy trình xử lý kết quả để hiển thị theo tiêu chuẩn
Xử lý kết quả phức tạp hơn chuyển đi một câu hỏi truy vấn. Một khi các biểu ghi được truy xuất, khổ mẫu của chúng cần thiết được chuyển đổi vào một khổ mẫu chung. Sự chuyển đổi tất cả các kết quả vào một khổ mẫu thống nhất đem lại một số lợi ích:
· Một hiển thị thống nhất các biểu ghi mà chúng thường khác biệt do sự ảnh hưởng bởi giao diện gốc của tài nguyên mục tiêu
· Khả năng so sánh các biểu ghi, cho phép sắp xếp theo sự phù hợp cũng như kết hợp lại và loại bỏ trùng lặp trong danh mục kết quả cho dù biểu ghi trong các danh mục đó bắt nguồn từ các tài nguyên khác biệt nhau.
· Xây dựng một đường dẫn OpenURL cho phép phát sinh các nối kết phù hợp ngữ cảnh (context-sensitive linking) tới các dịch vụ khác.
Tiếp đó, xử lý kết quả đòi hỏi một bộ quy luật cần được tuân thủ, các quy luật cho phép phần mềm ánh xạ trường dữ liệu chính xác, chuyển đổi các bộ ký tự, phân tích cú pháp trường dữ liệu để xuất ra siêu dữ liệu phù hợp cho việc sinh ra một đường dẫn OpenURL, và nhiều yêu cầu khác nữa.
Giả sử, một trường dữ liệu trông giống như dưới đây:
< Journal abbreviated name > < month > / < month > < year >, Vol.< volume > Issue < issue >, p < page >
Và ở đây là hai ví dụ của những trích dẫn như vậy:
Macrobiotics Today May/June2002, Vol. 42 Issue 3, p25
Health June2002, Vol.16 Issue 5, p120
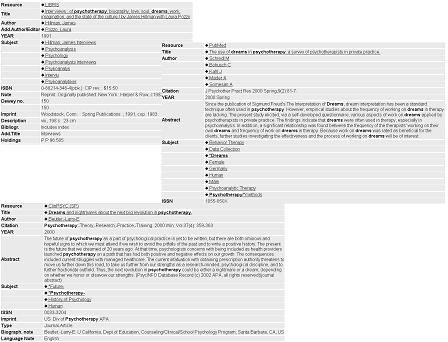
Thủ thư kích hoạt các quy luật sau để trích xuất thông tin cần thiết (Xem Hình 3):
(1) Tên tạp chí ở trong vị trí đầu tiên và kết thúc trước tên của một tháng
(2) Tên của một tháng được tiếp theo bởi năm nếu không có dấu “/”. Một năm có bốn chữ số.
(3) Sau chuỗi ký tự “Vol.” là số quyển, và tiếp đó là một khoảng trống
(4) Sau chuỗi ký tự “issue” là số xuất bản định kỳ, và tiếp sau đó là một khoảng trống
(5) Sau chuỗi ký tự “p” tiếp sau là số trang bắt đầu.
Khi cấu hình một tài nguyên mới, thì đòi hỏi phải gán một quy luật phù hợp. Ex Libris có thể cấu hình những tài nguyên mới và làm chúng sẵn có, hoặc một thủ thư có thể thêm vào các tài nguyên mới và biên tập quy luật khi cần thiết. Quy trình này không đòi hỏi viết một chương trình, thay vì chứa đựng hàng trăm hay hàng nghìn chương trình để biên dịch biểu ghi cho mỗi tài nguyên, thì một mặt, MetaLib cung cấp một KnowledgeBase, và mặt khác, cung cấp một Universal Gateway. Universal Gateway là một chương trình giàu chức năng có khả năng hiểu bản chất của mỗi tài nguyên và tuân thủ các quy luật tìm thấy trong KnowledgeBase. Như Berners-Lee (2001) đã tóm tắt: “Một máy tính không thể thực sự “hiểu được” bất kỳ dạng thông tin này, song nó giờ đây có thể thao tác những thuật ngữ hiệu quả hơn nhiều để trình bày theo nhiều cách hữu ích và có ý nghĩa đối với người dùng”.
Hình 3: Sự hiển thị thống nhất diễn ra một khi các biểu ghi đã truy xuất được biên dịch phù hợp với thông tin chức năng chứa đựng trong KnowledgeBase.
 |
Kết luận
Thách thức của một nhà cung cấp một công nghệ cổng thư viện như MetaLib là nhằm cung cấp những giải pháp sẽ hoạt động tốt vào thời điểm này và tương lai, bất kể thiếu tiêu chuẩn, song nó vẫn sẵn sàng cho sự hứa hẹn cho một thế hệ Web ngữ nghĩa.
Thông qua sử dụng công nghệ này, giải pháp MetaLib đã chứng minh ở nhiều site trên khắp thế giới rằng khái niệm hỗ trợ cho Web ngữ nghĩa này quả thật đã đem lại hiệu quả. Một số ví dụ triển khai đã được thấy nhiều trên Web (như Boston College University Libraries (https://databases.bc.edu/V), Massachusetts, USA, National Library of the Czech Repulic (CNL – http://www.jib.cz/V?RN=860193299), Curtin University, Australia (Gecko – http://gecko.curtin.edu.au/V, Cooperative Library Network Berlin – Brandenburg, Germany (KOBV Portal), UEA University of East Anglia, UK – (http://mlsfx.lib.uea.ac.uk/V).
Kho dữ liệu KnowlegeBase đã chứng tỏ là phương pháp duy trì và thực hành khi triển khai khái niệm Web ngữ nghĩa trong thời gian này. Cấu trúc KnowledgeBase và các chức năng chứa đựng trong nó đã cho phép thư viện cài đặt các cổng tài nguyên nhanh chóng, đồng thời tận dụng được KnowledgeBase trung tâm như là cơ sở tương tác với các tài nguyên mục tiêu, và đưa vào đó ngữ cảnh đặc thù và yêu cầu quản trị riêng của thư viện. Hơn thế nữa, chính KnowledgeBase bao gồm một tài nguyên giá trị có tính tiềm năng mà các chương trình máy tính có thể truy cập trong một ngữ cảnh không sử dụng MetaLib để trích xuất thông tin chứa đựng trong đó.
Xây dựng một ứng dụng như MetaLib là một bước đi quan trọng hướng tới triển khai khái niệm Web ngữ nghĩa trong môi trường tài nguyên học thuật. Một bước đi lớn hơn nữa đó nó sẽ xây dựng một kho thông tin tài nguyên thật hữu ích trong tương lai. Bước đi này là thách thức đáng kể đối với nhà cung cấp , khi mà không ai có thể dự đoán được mọi thứ sẽ diễn ra như thế nào trong năm hay mười năm tới.
Tamar Sadeh và Jenny Walker
Theo tạp chí New Library World, Q. 104, Số 1184/1185, 2003, tr. 11-19, Emerald Publishing Limited